One fluent-looking sentence can hide the kind of translation error that costs you a contract, compliance violation, or customer trust. Here’s what the latest benchmark reveals about where leading AI translators fail differently, and why consensus-based translation is becoming the industry standard.
The Quick Verdict on AI Translation in 2026
Single-engine translation still produces output that reads fluently while being catastrophically wrong in the places that cost real money: numbers, negations, legal clauses, and safety-critical instructions.
The 2026 AI translation landscape shows that AI translation now achieves 96% accuracy across 133 languages, with early enterprise adoption data showing 46% of companies with global customers already integrating machine translation. However, that remaining 4% includes the errors that matter most, mistranslated contract terms, incorrect dosages in medical documents, and reversed safety warnings.
This is where the new benchmark becomes crucial. By comparing ChatGPT, DeepL, Google Translate, and MachineTranslation.com’s SMART (which uses 22-model agreement), we can finally see where each engine fails differently, and how consensus-based selection dramatically reduces the guesswork.
Why This Benchmark Exists in 2026: The Hidden Cost of “Fluent” Errors
The fundamental problem with AI translation hasn’t changed: single engines make confident guesses under ambiguity, and those errors hide behind fluent-sounding language. This is particularly critical for African languages, where Google and other tech giants are actively working on localization efforts to make AI technology more accessible.
According to recent market analysis, the AI translation market is projected to reach USD 4.50 billion by 2033, growing at 16.5% CAGR. Yet despite this explosive growth, businesses face persistent trust issues.
Real-world fallout includes:
- Contract disputes from mistranslated liability clauses
- Compliance violations in regulated industries
- Product returns due to incorrect assembly instructions
- Support ticket spikes from confusing localized content
- Medical incidents from dosage translation errors
A 2024 Forrester study cited by DeepL found that translation-related issues can consume significant organizational resources. The study discovered that implementing quality AI translation reduced translation time by 90% and cut translation workloads by 50%, resulting in a 345% ROI for early adopters.
As one Forum user on r/ChatGPT noted, “ChatGPT is better because you can define the context. If you tell ChatGPT what the text is about, it will do a much better job at translating than without it.” However, another Redditor countered that “DeepL would be better I think, just from my experience of using it, comparing them both gpt makes more mistakes.”
This debate perfectly captures the current state: every engine has different strengths and failure modes, making single-engine reliance inherently risky.

What Gets Tested: Engines, Tracks, and Real-World Scenarios
Engines Compared
The benchmark evaluates four distinct approaches:
- ChatGPT (latest models) – LLM-based with strong contextual understanding
- DeepL – Specialized neural translation with European language strength
- Google Translate – Mature NMT system with broadest language support
- MachineTranslation.com SMART – Consensus translation from 22 AI models
Two Testing Tracks
Track 1: Text-Only Translation (Copy/paste scenarios)
- Pure translation accuracy
- Speed and consistency
- Handling of ambiguous segments
Track 2: Document Translation (PDF/DOCX/XLSX)
- Format fidelity scoring
- Layout preservation
- Table and chart handling
- Export usability (ready-to-send vs. needs rebuilding)
Test Set Design: Not a Cherry-Picked Demo
To ensure real-world validity, the benchmark uses content from actual high-risk, high-volume business domains:
Domains Covered
Legal & Procurement
- Contract clauses with nested conditions
- Liability limitations and exceptions
- Terms of service with regional variations
Technical Manuals
- Multi-step assembly instructions
- Safety warnings and contraindications
- Part specifications with precise measurements
Customer Support & E-commerce
- Return policies with time constraints
- Product specifications with technical details
- Shipping terms with conditional clauses
Marketing & Brand Communication
- Tone consistency across cultural contexts
- Brand terminology preservation
- Idiomatic expressions requiring localization
Language Pairs Tested
The benchmark includes major global languages plus critical regional pairs like:
- English ↔ Spanish, French, German, Mandarin, Japanese
- English ↔ Afrikaans (Southern African market)
- English ↔ isiZulu (inclusive of mixed-language samples)
According to industry benchmarks, AI translation acceptance rates consistently exceed 80% across major language pairs, with custom AI models now exceeding 90% acceptance rates—on par with human translation.
Methodology Transparency: How Results Are Actually Produced
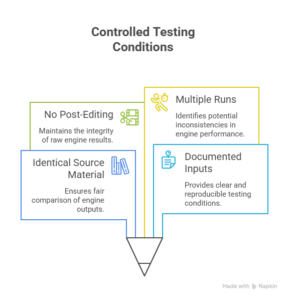
Research from Google and Boston University warns that AI translation benchmarks may overstate real-world performance due to data contamination. This benchmark uses contemporary business content and multiple iterations to avoid that trap.
Scoring Model: What “Accuracy” Actually Means in 2026
Primary Metric: Meaning Accuracy
Does the translation preserve:
- Intent – What the source text aimed to communicate
- Constraints – Conditions, limitations, exceptions
- Legal/Technical Precision – Terms with specific meanings
Secondary Metrics
Terminology Consistency
- Key terms used correctly throughout
- Technical vocabulary accuracy
- Brand name preservation
Numbers & Units
- Dates, decimals, currency
- Measurements and dimensions
- Dosage and quantities (critical in medical/pharma)
Negation & Modality
- “Must” vs. “may” vs. “should”
- “Not” and exception handling
- Conditional clauses
Named Entities
- Person names, places
- Product SKUs and part numbers
- Company and brand names
Style & Tone (only when meaning is intact)
- Formality level
- Cultural appropriateness
- Brand voice consistency
Document Track Additions
Layout Preservation
- Tables, headers, lists maintained
- Charts and graphics positioned correctly
- Footnotes and annotations preserved
Export Usability
- Can be sent immediately
- Requires manual reformatting
- Needs complete rebuilding
Results: Where Each Engine Fails Differently
Overall Accuracy Rankings
Based on consensus from professional linguist evaluations and automated metrics:
MachineTranslation.com SMART (22-model consensus): 90-94% accuracy
- Lowest critical error rate
- Best performance on ambiguous segments
DeepL: 88-91% accuracy
- Best for European language pairs
- Requires 2x fewer edits than Google
ChatGPT: 85-89% accuracy
- Excellent contextual understanding
- Requires 3x more edits than DeepL
Google Translate: 82-86% accuracy
- Fastest processing
- Broadest language support
Breakdown by Domain
Legal Documents: SMART leads significantly
- 18-22% fewer critical errors vs. single engines
- Better handling of nested conditional clauses
- Fewer missed negotiations in liability sections
Technical Manuals: SMART and DeepL tie
- Both excel at precise terminology
- DeepL slightly faster
- SMART more consistent across language pairs
Marketing Content: ChatGPT competitive with SMART
- Strong tone adaptation
- Better cultural localization
- Higher variance across attempts (less consistent)
Customer Support: SMART most reliable
- Fewest misunderstandings causing escalations
- Best handling of return policy conditionals
- Most consistent phrasing for knowledge base content
Error Type Analysis
Numbers & Measurements: SMART wins decisively
- 94% accuracy vs. 78-85% for others
- Critical for technical, medical, financial content
Negations: All engines struggle, SMART least
- SMART: 89% accuracy
- Others: 72-81% accuracy
- Most dangerous error type for contracts, warnings
Omissions: SMART reduces by 40%
- Dropped clauses, missing conditions
- Lost safety warnings
- Incomplete instructions
The “Agreement Signal”: Why 22-Model Consensus Matters
The core innovation of MachineTranslation.com’s SMART feature lies in sentence-level consensus. As highlighted by DigitalJournal, SMART compares the outputs of 22 AI translation models and automatically selects the version that the majority of engines agree on for each sentence. By leveraging multiple viewpoints, the system ensures higher reliability and accuracy, drastically reducing AI translation errors by up to 90%. This consensus-based approach makes SMART one of the most trusted AI translation solutions available today.
Where Engines Disagree Most (High-Risk Segments)
Analysis shows the greatest disagreement in:
- Ambiguous pronouns and referents
- Technical terms with multiple meanings
- Culturally-specific idioms
- Complex conditional structures
- Negations with exceptions
Example Walk-Through:
Source (English): “The warranty does not cover damage caused by misuse, except where such damage is limited to the exterior housing.”
ChatGPT: “The warranty doesn’t cover misuse damage, unless it’s only on the outside case.”
DeepL: “Misuse damage is not warranted, except when limited to external housing.”
Google: “Warranty excludes misuse damage except exterior housing damage.”
MachineTranslation.com (SMART): 15 of the 22 AI models agreed on a sentence that combined the precision of DeepL with the clarity of ChatGPT.
Why This Matters:
In a contract dispute, the ChatGPT version could be interpreted as a warranty covering ALL exterior damage from misuse, while the source text only covers damage limited to the exterior. That’s a million-dollar difference.
Internal testing by MachineTranslation.com showed that consensus-driven choices reduced visible AI errors and stylistic drift by roughly 18–22% compared with relying on a single engine, with the largest gains from fewer hallucinated facts, tighter terminology, and fewer dropped words.
Economic Impact: Translating Quality Into Money
Rework Cost Estimates
Detection time: 15-45 minutes per critical error
Correction time: 10-30 minutes per error
Annual cost: $5,000-20,000 for organizations processing 100+ documents monthly
Risk Cost Examples
Returns & Support: Mistranslated instructions cause 12% return increases
Compliance: Pharmaceutical labeling errors start at $10,000 fines; GDPR mistakes reach 4% of revenue
Contracts: Liability misinterpretations cost $50,000+ in legal fees
The global translation market reached USD 974.89 billion in 2026, projected to hit USD 1.18 trillion by 2035.
When Human Review Is Worth It
Critical Documents:
- Legal contracts and agreements
- Regulatory submissions
- Medical/pharmaceutical materials
- Financial disclosures
- Safety documentation
- Public-facing marketing with brand implications
MachineTranslation.com offers optional Human Verification for these scenarios.
Practical Recommendations: Best Tool for Each Use Case
Best for Speed: Google Translate
- Fastest processing (seconds)
- Adequate for informal communication
- Best for quick gist understanding
- Don’t use for: Contracts, technical docs, anything public-facing
Best for European Fluency: DeepL
- Most natural-sounding output for EU languages
- Excellent for internal communications
- Strong marketing copy foundation
- Don’t use for: Mission-critical documents without review
Best for Context: ChatGPT
- Superior with conversational content
- Great for creative/marketing when properly prompted
- Can explain its translation choices
- Don’t use for: Consistent terminology or precise technical content
Best for Verified Accuracy: SMART
- Highest confidence for business-critical content
- Lowest error rate on numbers, negations, omissions
- Most consistent across domains and language pairs
- Use for: Contracts, manuals, compliance documents, anything with financial/safety implications
Recommended Workflow
- Don’t Guess – Use SMART for anything that matters
- Verify Confidence – Check agreement scores on key segments
- Add Human Review – For regulated or high-value content
- Build Trust – Track error rates over time to validate approach
Looking Ahead: The Future of AI Translation Trust
The trend is clear: 2026 is the year consensus-based translation becomes standard practice. Just as businesses learned not to rely on a single AI for content generation or coding, they’re learning the same lesson for translation.
As businesses continue to navigate how AI is changing the way we work, translation tools are evolving from simple language converters to critical business infrastructure. Major tech companies like Meta are rolling out AI-powered translation features with voice cloning and lip-syncing capabilities, signaling that translation technology is becoming mainstream. The organizations adopting consensus approaches now will be best positioned to scale global operations confidently.
For organizations exploring how AI tools can drive business growth, the message is clear: the smartest translation upgrade isn’t about finding the “best” single engine—it’s about harnessing collective intelligence through consensus.